Moore’s Law describes the explosion in processing power driving the current progress in scientific computing. This power enables the next-generation algorithms for adaptive vision testing that serve Manifold®. The foundation of Manifold®, the qCSF algorithm, is built on a computational framework that combines Bayesian adaptive inference and an information-maximization strategy. The framework uses a person’s test history to optimally adapt testing to their unique visual profile, using personalized, informative combinations of spatial frequency and contrast.
The power of the qCSF algorithm starts with a broad Bayesian foundation that can describe the wide range of population variability of contrast sensitivity performance: from low vision to elite vision. Before the quantitative CSF begins, the patient’s vision is described in a combinatorial space of millions of candidate functions. These different sequences and combinations effectively represent millions of different potential contrast sensitivity charts. Given all these possible tests, how do you choose which is the right one for each individual?
-
A patient’s vision can be described in a combinatorial space of millions of candidate functions. How can vision testing focus on each patient?
-
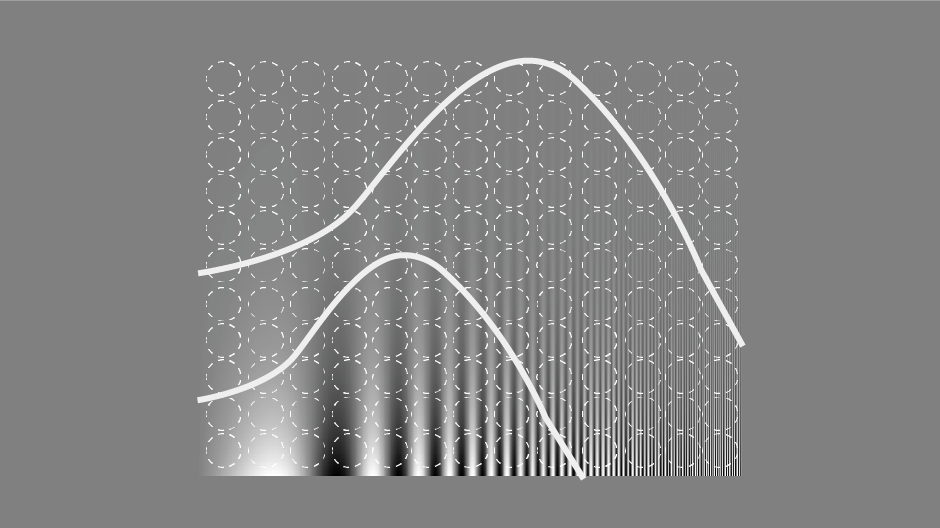
A powerful adaptive algorithm uses a person’s test history to adapt testing to their unique visual profile using optimally personalized, informative combinations of spatial frequency and contrast.
-

Personalized, optimized sampling, which rapidly converges on different profiles of contrast sensitivity, reduces testing times without sacrificing precision.
Personalizing each test is accomplished by a complex algorithm that narrows the search for the right test combinations (letter sizes and contrasts) to refine the estimate of the personalized function in the space of candidate functions. This is accomplished by adaptively inferring the best combinations, with a search in the stimulus space of contrast sensitivity testing.
Not long ago, the realtime computational complexity of this algorithm would have required a supercomputer in the doctor’s office.
The space of candidate CSFs is evaluated by an intense search of the space of possible contrast sensitivity tests. Just as a search engine can provide relevant options as you type in a sequence of search terms, after a few trials the quantitative CSF estimates the general shape of the individual’s contrast sensitivity function.
The qCSF algorithm uses intense computing power to narrow down the space to a very precise estimate of a patient’s probable CSF. There is a large space of possible stimuli. What part of the stimuli space is appropriate? Our test finds the part of the space that tells us about this person. We don’t waste time testing irrelevant points.
By focusing on the test history of each individual, personalized CSF, the quantitative CSF provides the precision to track and monitor visual changes in each individual.
The quantitative CSF algorithm is built on research showing that the contrast sensitivity function requires four parameters to define its global shape: two parameters describe the peak (x- and y-coordinates), one describes its width, and one describes its low-frequency plateau.
Taking these four parameters, we generate the complete set of candidate CSFs from all possible four-parameter combinations that can be computed, given a person’s full trial history.
Before each trial, the expected information gain is calculated for all possible stimuli over the space of candidate CSFs, and people are only shown stimuli that will reveal new information.
Figure 4
Contrast sensitivity is described by the truncated log-parabola model as a function of spatial frequency. Four parameters are represented: the peak gain (ymax), the peak frequency (fmax), the bandwidth (beta), and the low-frequency plateau (delta).
There is not much learned if testing focuses on visual targets that are obviously recognized correctly or incorrectly. By intensely focusing on the boundary between the visible and invisible, and not wasting time on obviously visible or obviously invisible testing, the quantitative CSF can easily estimate the whole CSF in 3–5 minutes (25–50 trials). This enables rapid, precise testing of CSF in labs, clinics, and eventually, in the home.